Base de données relationnelle
I. Histoire
II. Définition
II Les terme de base de données relationnelle
1. Relation ou tables
2. Contraintes
3. Clés (Keys)
4. Clé primaire
5. Clé étrangère
6. Indice
7. Algèbre relationnelle
8. Normalisation
IV. Voir Aussi
-----------------------------------------------------------------------------------------------------------------------------------------------------------
I.Histoire
En 1970, Edgar F. Codd, un mathématicien diplômé d'Oxford qui travaillait au laboratoire de recherche de IBM San Jose, a publié un document montrant comment les informations stockées dans des grandes bases de données pourrait être accessible sans savoir comment l'information a été structuré ou où il résidait dans la base de données.
Jusque-là, la récupération d'informations nécessite de connaissance informatique relativement sophistiqué, ou même les services de spécialistes qui savaient comment écrire des programmes pour aller chercher de l'information une tâche spécifique prennent du temps et de l'argent.
Les Bases de données qui ont été utilisées pour récupérer la même information à plusieurs reprises, et d'une manière prévisible -comme une facture de matériaux pour la fabrication-étaient bien établis à l'époque. Ce que a fait Codd était d’ouvrir la porte à un nouveau monde de l'indépendance des données. Les utilisateurs ne doivent être des spécialistes, pas plus qu'ils ont besoin de savoir où l'information était ou comment l'ordinateur a récupérée. Ils peuvent désormais se concentrer davantage sur leurs entreprises et moins sur leurs ordinateurs.
Codd a appelé son papier, "Un Modèle Relationnel De Données Pour Les Banques De Grandes Données Partagés." Les informaticiens ont appelé une «idée révolutionnaire."
Aujourd'hui, la facilité et la flexibilité de bases de données relationnelles entre eux ont fait le choix prédominant pour les dossiers financiers, de la fabrication et des informations logistiques, et les données du personnel. La plupart des données de routine des transactions accèdent à des comptes bancaires, en utilisant des cartes de crédit, les stocks commerciaux, faire des réservations de voyage, acheter des choses en ligne-toutes les structures d'utilisation basée sur la théorie de base de données relationnelle.
L'idée de Codd a engendré une nouvelle famille de produits pour IBM, centrée sur le système IBM ® DB2 ® Gestion de base de données, ainsi que le langage informatique standard de l'industrie pour travailler avec des bases de données relationnelles, appelé SQL(Structured Query Language en français langage de requête structurée).
Selon la notice nécrologique du New York Times pour Codd, "... avant le travail du Dr Codd a trouvé son chemin dans des produits commerciaux, des bases de données électroniques étaient« complètement temporaire et pêle-mêle, dit Chris Date, un expert de données relationnelle qui a travaillé sur DB2 au IBM avant de devenir un partenaire d'affaires de Dr. Codd ".
Comme beaucoup d'idées révolutionnaires, la base de données relationnelle ne sont pas venus aussi facilement.
Dans les années 1960, la grande quantité de données stockées dans de nouveaux ordinateurs-plusieurs centraux du monde d'entre eux IBM System / 360 machines- était devenu un problème. Calculs centraux étaient chers, coûtant souvent des centaines de dollars US par minute. Une partie importante de ce coût était la complexité entourant la gestion de base de données.
Codd, qui avait ajouté un doctorat en informatique à son bagages mathématiques quand il est venu aux États-Unis de son pays natale "Angleterre", a partit pour résoudre ce problème. Il a commencé avec une prémisse simple et élégante: Il voulait être en mesure de demander à l'ordinateur pour obtenir des informations, et laisser ensuite la l'ordinateur figure où et comment l'information est stockée et comment la récupérer.
Don Chamberlin d'IBM a déclaré que «l'idée de base de Codd était que les relations entre les éléments de données devraient être basées sur les valeurs de l'objet, et non pas sur des liaisons spécifiés séparément ou de nidification. Cette notion grandement simplifié la spécification de requêtes et a permis une flexibilité pour exploiter des ensembles de données existants dans de nouveaux moyens ".
Dans son article fondateur, Codd a écrit qu'il a utilisé le terme relation dans le sens mathématique de la théorie des ensembles, comme dans la relation entre les groupes des ensemble. En termes clairs, sa solution de base de données relationnelle a fourni un niveau d'indépendance de données qui permet aux utilisateurs d'accéder aux informations sans avoir à maîtriser les détails de la structure physique d'une base de données.
Aussi excitant que la théorie était à la communauté technique, il était encore une théorie. Il devait être minutieusement testé pour voir si et comment il fonctionnait. Depuis plusieurs années, IBM a choisi de continuer la promotion de son système de base de données hiérarchique établie, IBM IMS (Information Management System). Un système hiérarchique utilise une structure arborescente pour les tableaux de données. Alors que IMS peut être plus rapide que DB2 pour les tâches courantes, il peut exiger plus d'efforts de programmation pour concevoir et maintenir des tâches non-primaires. Les Bases de données relationnelles ont prouvés la supériorité dans les cas où les demandes changent fréquemment ou qui nécessitent une variété de perspectives "angles."
IBM, Rockwell et Caterpillar développés IMS en 1966 pour aider à suivre les millions de pièces et matériaux utilisés dans Programme spatial Apollo de la NASA. Il continue d'être la première base de données hiérarchique système de gestion d'IBM.
En 1973, le Laboratoire de recherche San Jose -maintenant Almaden Research Center-a commencé un programme appelé Système R (R pour relationnelle) pour prouver la théorie relationnelle avec ce qu'il a appelé «industrial-strength implementation .» Le projet a produit une sortie extraordinaire des inventions qui est devenu le fondement de la réussite d'IBM avec des bases de données relationnelles.
Don Chamberlin et Ray Boyce inventé SQL ,pour Structured Query Language, aujourd'hui, est le language le plus largement utilisé pour les requêtes de bases de données relationnelles. Patricia M. Selinger a développé un optimiseur de coûts, ce qui rend le travail avec les bases de données relationnelles plus coût-efficaces et efficients. Et Raymond Lorie inventé un compilateur qui sauve les plans de requête de base de données pour une utilisation dans le future.
En 1983, IBM a introduit la famille DB2 de bases de données relationnelles, ainsi nommé parce qu'il était deuxième famille d'IBM de logiciels de gestion de base de données. Aujourd'hui, bases de données DB2 traitent des milliards de transactions chaque jour. Il est l'un des produits les plus réussis de logiciels d'IBM. Selon Arvind Krishna, directeur général de la gestion de l'information IBM, DB2 continue d'être un chef de file en logiciels innovants de base de données relationnelle.
II. Définition:
Une base de données relationnelle est un ensemble de tableaux contenant des données équipés en catégories prédéfinies. Chaque table (qui est parfois appelé une relation) contient une ou plusieurs catégories de données en colonnes. Chaque ligne contient une instance unique de données pour les catégories définies par les colonnes. Par exemple, une base de données typique de la saisie des commandes de l'entreprise devrait inclure une table qui décrit un client avec des colonnes pour le nom, l'adresse, le numéro de téléphone, et ainsi de suite. Une autre table décrirait un ordre: produit, client, date, prix de vente, et ainsi de suite. Un utilisateur de la base de données pourrait obtenir une vue de base de données qui répond aux besoins de l'utilisateur. Par exemple, un chef de bureau d'une branche pourrait aimer une vue ou un rapport sur tous les clients qui avaient acheté des produits après une certaine date. Un directeur des services financiers dans la même entreprise pourrait, à partir des mêmes tables, obtenir un rapport sur les comptes qui devaient être payés.
Lors de la création d'une base de données relationnelle, vous pouvez définir le domaine de valeurs possibles dans une colonne de données et les autres contraintes qui peuvent être appliquer à ce valeur des données. Par exemple, un domaine de clients possibles pourrait permettre à un maximum de dix noms de clients possibles, mais dans un seul tableau on permettra seulement trois de ces noms de clients d'être spécifier.
La définition de bases de données relationnelles se résume dans une table de métadonnées ou descriptions formelles des tables, des colonnes, des domaines et des contraintes.

Les Termes de base de données relationnelle
III.Les Termes de base de données relationnelle:
1.Relations ou tables
Une relation est définie comme un ensemble de tuples qui ont les mêmes attributs. Un tuple représente généralement un objet et d'informations sur cet objet. Les objets sont généralement des objets physiques ou des concepts. Une relation est généralement décrit comme un tableau, qui est organisé en lignes et en colonnes. Toutes les données référencées par un attribut sont dans le même domaine et sont conformes aux mêmes contraintes.
Le modèle relationnel précise que les tuples d'une relation ont pas d'ordre spécifique et que les tuples, à leur tour, n'imposent pas d'ordre sur les attributs. Les Applications accèdent aux données en spécifiant les requêtes qui utilisent des opérations telles que de sélectionner pour identifier tuples, projet visant à identifier les attributs, et de rejoindre de combiner les relations. Les relations peuvent être modifiés en utilisant l'insérer, supprimer, et les opérateurs de mise à jour. Nouveaux tuples peuvent fournir des valeurs explicites ou être dérivé d'une requête. De même, les requêtes de mise à jour identifient les tuples ou la suppression.
Les Tuples par définition sont unique. Si le tuple contient un candidat ou une clé primaire alors évidemment il est unique; Cependant, une clé primaire ne doit pas être défini pour une ligne pour être un tuple. La définition d'un tuple exige qu'il soit unique, mais ne nécessite pas une clé primaire à définir. Parce que un tuple est unique, ses attributs, par définition, constituent une super-clé.

base de données relationnelle avec 3 tables
2. Contraintes
Contraintes permettent de restreindre davantage le domaine d'un attribut. Par exemple, une contrainte peut restreindre un attribut entier donné à des valeurs entre 1 et 10. Les contraintes fournir une méthode de mise en œuvre de règles de gestion dans la base de données. SQL implémente des fonctionnalités de contrainte sous la forme de contraintes de vérification. Les contraintes limitent les données qui peuvent être stockées dans les relations. Ceux-ci sont habituellement définies en utilisant des expressions qui résultent en une valeur booléenne indiquant si oui ou non les données satisfait la contrainte. Les contraintes peuvent appliquer aux attributs simples, à un triplet (limitant combinaisons d'attributs) ou à une relation ensemble. Étant donné que chaque attribut a un domaine associé, il y a des contraintes (contraintes de domaine). Les deux règles principales pour le modèle relationnel sont connus comme l'intégrité de l'entité et de l'intégrité référentielle.
3. Clés (Keys)
Chaque ligne d'une table a sa propre clé unique. Lignes d'une table peuvent être liés à des lignes dans d'autres tables en ajoutant une colonne pour la clé unique de la ligne liée (ces colonnes sont connus comme des clés étrangères). Codd a montré que les relations de données de complexité arbitraire peuvent être représentés en utilisant cette simple ensemble de concepts.
Une partie de ce traitement consiste à toujours être en mesure de sélectionner ou de modifier une et une seule ligne dans une table. Par conséquent, la plupart des implémentations physiques ont, une clé primaire unique attribué par le système pour chaque table. Quand une nouvelle ligne est écrite dans la table, le système génère et écrit la nouvelle valeur, unique pour la clé primaire (PK); ce est la clé que le système utilise principalement pour accéder à la table. Les performances du système est optimisée pour PK (primary key =clé primaire). Les autres touches, plus naturels peuvent également être identifiés et définis comme clés alternatives (AK)(Alternative Key). Souvent, plusieurs colonnes peuvent être nécessaires pour former un AK (cela est une raison pour laquelle une colonne de seul entier est habituellement fait le PK). Les deux PK et AK ont la capacité d'identifier de façon unique une ligne dans une table. La technologie supplémentaires peut être appliquée ce qui assurera de façon significative un identifiant unique à travers le monde, un identificateur global unique; ceux-ci sont utilisés quand il y a des exigences en matière de système plus vaste.
Les clés primaires dans une base de données sont utilisés pour définir les relations entre les tables. Quand un PK migre vers une autre table, il devient une clé étrangère dans l'autre table. Lorsque chaque cellule peut contenir une seule valeur et le PK migre dans une table de l'entité régulière, ce modèle de conception peut représenter un seul à seul, ou une relation "seul-aux-beaucoup". La plupart des base de données relationnelle conçoit à résoudre un grand nombre à de nombreuses relations en créant une table supplémentaire qui contient les clés primaires à la fois de l'autre entité tables,la relation devient une entité; la table de résolution est alors nommé de manière appropriée et est souvent attribué à son propre PK tandis que les deux FK sont combinés pour former un AK. La migration de PK à d'autres tables est la deuxième raison majeure pour laquelle entiers affectés au système sont utilisés normalement comme PK; il est généralement ni l'efficacité ni la clarté dans la migration d'un tas de autres types de colonnes.
4. Clé primaire
Une clé primaire spécifie uniquement un tuple d'une table. Pour un attribut à être une bonne clé primaire, il ne doit pas répéter. Tandis que les attributs naturels (attributs utilisés pour décrire les données saisies) sont parfois des bonnes clés primaires, clés de substitution sont souvent utilisés à la place. Une clé de substitution est un attribut artificielle affectée à un objet qui l'identifie de manière unique (par exemple, dans une table d'informations sur les élèves d'une école ils pourraient tous être attribués une carte d'étudiant afin de les différencier). La clé de substitution n'a pas de sens (inhérente) intrinsèque, mais plutôt est utile par sa capacité à identifier de manière unique un tuple. Un autre phénomène fréquent, surtout en ce qui concerne N: M cardinal est la clé composite. Une clé est une clé composite constitué de deux ou plusieurs attributs dans une table que (ensemble) identifier de manière unique un enregistrement. (Par exemple, dans une base de données concernant les élèves, les enseignants et les classes. Les classes ont pu être identifiés de manière unique par une clé composite de leur nombre et leur temps à manger , car aucune autre classe pourrait avoir exactement la même combinaison d'attributs. En fait, l'utilisation d'une clé composite tel que cela peut être une forme de vérification des données, même faible.
5. Clé étrangère
Une clé étrangère est un champ dans une table relationnelle qui correspond à la colonne de clé primaire d'une autre table. La clé étrangère peut être utilisé pour les tables de références croisées. Les clés étrangères ne doivent pas avoir des valeurs uniques dans la relation de référencement. Les clés étrangères utilisent efficacement les valeurs des attributs dans le rapport rapporté à limiter le domaine d'un ou plusieurs attributs de la relation de mise en référence. Une clé étrangère peut être décrite officiellement comme: "Pour toutes les lignes dans la relation de référencement projetés sur les attributs de référencement, il doit exister un tuple dans la relation référencé projetée sur ces mêmes attributs tels que les valeurs de chacun des attributs référençant correspondre à la correspondante valeurs dans les attributs référencés ".
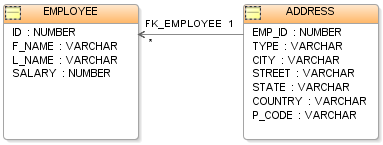
Base de données avec deux tables et une clé étrangère
6. Indice
Un index est un moyen de fournir un accès plus rapide aux données. Les Indices peuvent être créés sur une combinaison d'attributs sur une relation. Les requêtes qui filtre à l'aide de ces attributs peuvent trouver des lignes correspondantes à l'aide de l'index au hasard, sans avoir à vérifier chaque tuple à son tour. Ceci est analogue à l'aide de l'index d'un livre pour aller directement à la page sur laquelle les informations que vous cherchez se trouve, de sorte que vous ne devez pas lire le livre entier pour trouver ce que vous cherchez. Les Bases de données relationnelles fournissent généralement plusieurs techniques d'indexation, dont chacune est optimale pour une certaine combinaison de la distribution de données, la taille du rapport, et le modèle d'accès typique. Les indices sont généralement mis en œuvre par l'intermédiaire d'arbres B+arbres, R-arbres, et des bitmaps. Les Indices sont généralement pas considérés comme une partie de la base de données, car ils sont considérés comme un détail de mise en œuvre, même si les indices sont généralement maintenus par le même groupe qui maintient les autres parties de la base de données. Il convient de noter que l'utilisation des indices efficaces sur les deux clés primaires et étrangères peut améliorer considérablement les performances des requêtes. Ceci est parce que l'index B-arbres entraîne des temps d'interrogation proportionnelle à log (n) où n est le nombre de lignes dans une table et des index se résulte dans les requêtes de temps constants ( aucune taille dépendance tant que la partie pertinente de l'indice inscrit dans mémoire).
7. Algèbre relationnelle
L'Algèbre relationnelle est un langage de requête de procédure, qui prend les instances de relations en tant qu'entrée et produit les instances de relations en tant que sortie. Il utilise des opérateurs d'effectuer des requêtes. Un opérateur peut être soit unaire ou binaire. Ils acceptent les relations comme leurs relations d'entrée et de rendement comme leur sortie. L'Algèbre relationnelle est récursive sur une relation et des résultats intermédiaires sont également considérés comme des relations.
Les opérations fondamentales de l'algèbre relationnelle sont les suivants -
Sélectionner (Select)
Projeter (Project )
Union (Union)
Détermination différent ( Set different)
produit cartésien (Cartesian product)
Renommer (Rename)
Nous allons discuter toutes ces opérations dans les sections suivantes.
Sélectionnez l'opération (σ)
Il sélectionne les tuples qui satisfont le prédicat donné d'une relation.
Notation - σp (r)
Où σ est synonyme de sélection prédicat et R représente relation. p est la formule logique propositionnelle qui peut utiliser des connecteurs comme et, ou, et non. Ces termes peuvent utiliser les opérateurs relationnels comme - =, ≠, ≥, <,>, ≤.
Par exemple -
σsubject = "base de données" (Livres)
Output - Sélectionne les tuples de livres dont le sujet est 'base de données'.
σsubject = "base de données" et le prix = "450" (Livres)
Output - Sélectionne les tuples de livres dont le sujet est «base de données» et «prix» est de 450.
σsubject = "base de données" et le prix = "450" ou l'année> "2010" (Livres)
Output - Sélectionne les tuples de livres dont le sujet est «base de données» et «prix» est de 450 ou ces livres publiés après 2010.
Opération de projet (Π)
Il projette le(s) colonne(s) qui satisfont un prédicat donné.
Notation - ΠA1, A2, An (r)
Où A1, A2, An sont les noms des attributs de relation r.
Les lignes dupliquées sont automatiquement éliminés, comme relation est un ensemble.
Par exemple -
Πsujet, auteur (Livres)
Sélectionne et projets colonnes nommées comme sujet et auteur de la relation livres.
Opération Union (∪)
Il effectue Union binaire entre deux relations données et est définie comme -
r ∪ s = {t | t ∈ r ou t ∈ s}
Notion - r U s
Où r et s sont des relations de base de données ou de la relation résultante (relation temporaire).
Pour une opération d'union soit valide, les conditions suivantes doivent être tenue -
r, s et doivent avoir le même nombre d'attributs.
Les Domaines d'attributs doivent être compatibles.
Les Tuples dupliqués sont automatiquement éliminés.
Π auteur (Livres) ∪ Π auteur (Articles)
Output - Projets les noms des auteurs qui ont soit écrit un livre ou un article ou deux.
Set Différence (-)
Le résultat de l'opération Set différence est les tuples, qui sont présents dans un rapport, mais ne sont pas dans la seconde relation.
Notation - r - s
Trouve tous les tuples qui sont présents dans r, mais pas à l'art.
Π auteur (Livres) - Π auteur (Articles)
Output - Fournit le nom des auteurs qui ont des livres, mais pas des articles écrits.
Produit cartésien (Χ)
Combine des informations de deux relations différentes en un seul.
Notation - r Χ s
Où r et s sont des relations et de leur production seront définis comme -
r Χ s = {q t | q ∈ R et t ∈ s}
σauthor = 'tutorialspoint »(Livres Χ Articles)
Output - Rendements d'une relation, qui montre tous les livres et articles écrits par tutorialspoint.
Renommez l'opération (ρ)
Les résultats de l'algèbre relationnelle sont également des relations, mais sans nom. L'opération de changement de nom nous permet de renommer le rapport de sortie. 'renommer' opération est notée avec une petite lettre grecque rho ρ.
Notation - ρ x (E)
Lorsque le résultat de l'expression E est enregistré avec le nom de x.
Les opérations supplémentaires sont -
Set intersection
Affectation (Assignment)
Rejoindre naturel (Natural join)
8. Normalisation
Normalisation a d'abord été proposé par Codd tant que partie intégrante du modèle relationnel. Il englobe un ensemble de procédures visant à éliminer les domaines non simples (valeurs non-atomiques) et la redondance (duplication) de données, ce qui empêche les anomalies de manipulation de données et la perte de l'intégrité des données. Les formes les plus courantes de la normalisation appliquée aux bases de données sont appelés les formes normales.
IV.Voir Aussi :